overfitting是甚麼呢?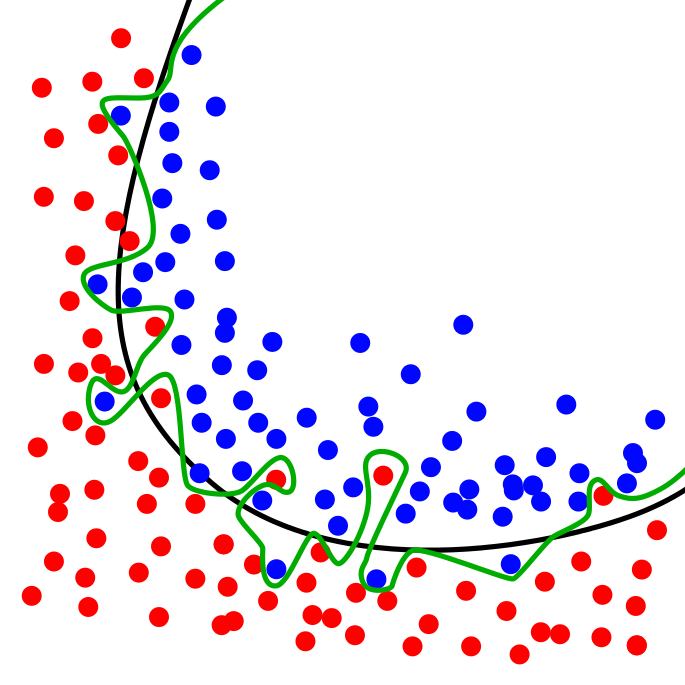
由上面的圖可以看的出來,有兩種資料分布,一種是紅色的,一種是藍色的,而半圓形有弧度的曲線則是我們比要好的機器學習的曲線,而綠色的不規則呢,則是太過偏激的選取那些特異的資料,導致機器學習的很不精確。
那,我們來看看overfitting由程式跑出來會是怎樣的吧
from sklearn.learning_curve import learning_curve
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
digits = load_digits()
X = digits.data
y = digits.target
train_sizes, train_loss, test_loss= learning_curve(
SVC(gamma=0.001), X, y, cv=10, scoring='mean_squared_error',
train_sizes=[0.1, 0.25, 0.5, 0.75, 1])
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
plt.plot(train_sizes, train_loss_mean, 'o-', color="r",label="Training")
plt.plot(train_sizes, test_loss_mean, 'o-', color="g",label="Cross-validation")
plt.xlabel("Training examples")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()
一樣,跟以往都一樣,把要用的東西引用近來,並用上節課的方式來檢測資料,cv=10就是分成十組,並用m
ean_squared_error來做測試,然後我們把測試出來的點在學習中是10% 25% 50%7 5% 100%做紀錄,然後將這些紀錄繪製成圖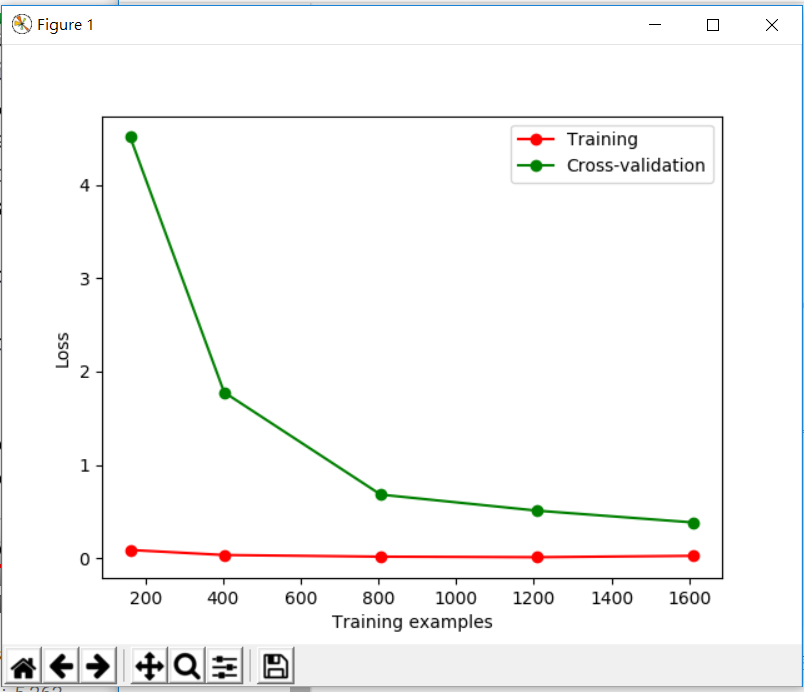 在圖中可以看到,誤差值越來越小,越學習越進步
在圖中可以看到,誤差值越來越小,越學習越進步
我們再來看看有問題的圖
我們將程式碼中的gamma參數調大,並執行程式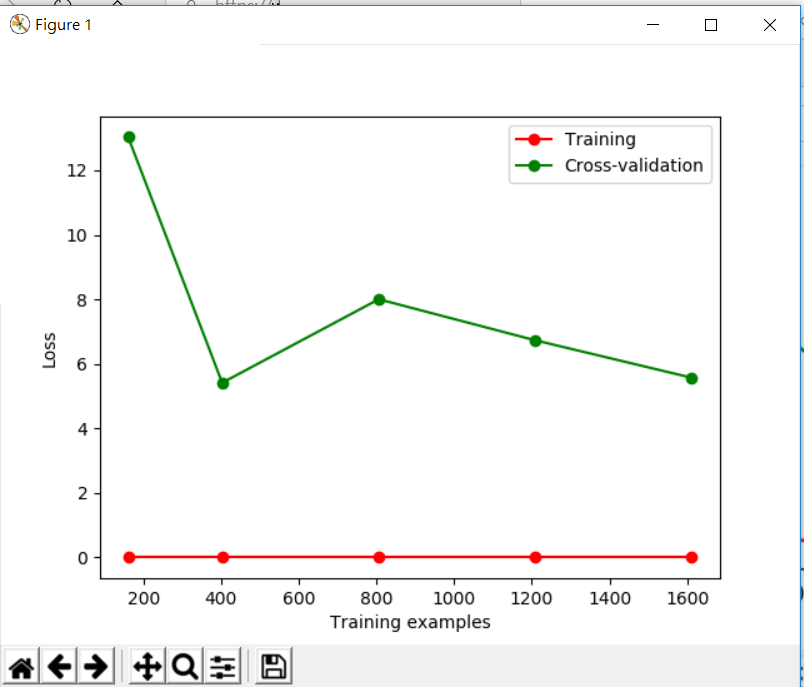 從上面圖可以看到,雖然它進步很快,但它的準確度卻很難再繼續進步,這就是太強調特異點而導致整體準確度的喪失
從上面圖可以看到,雖然它進步很快,但它的準確度卻很難再繼續進步,這就是太強調特異點而導致整體準確度的喪失