Scikit-Learn套件的思維模式
安裝好了Scikit-Learn之後,先別急著用,我們先來了解Scikit-Learn的思維模式,剛好官方網站提供了一個很好的流程圖,
如下:
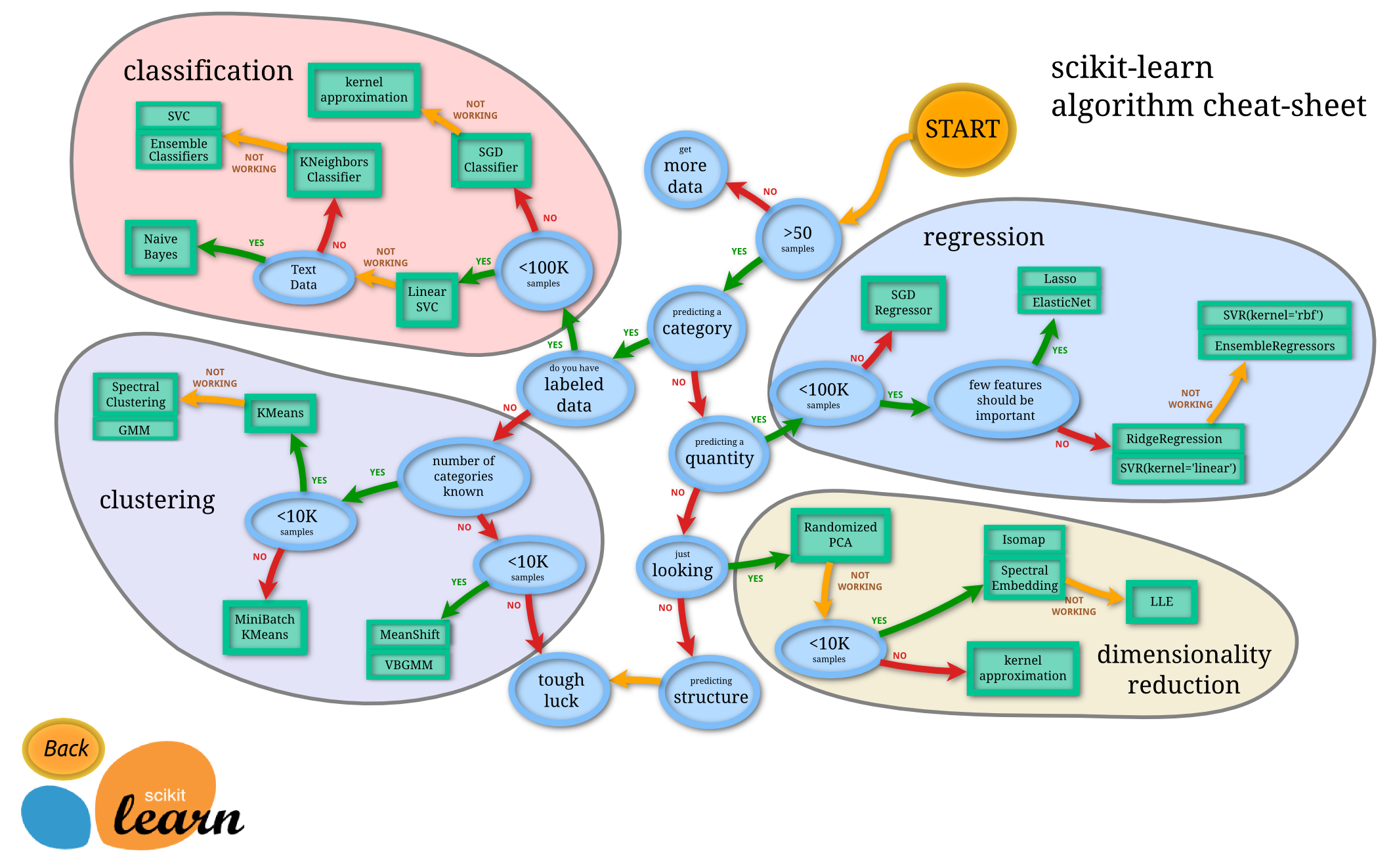 (圖片來源:http://scikit-learn.org/stable/tutorial/machine_learning_map/index.html)
(圖片來源:http://scikit-learn.org/stable/tutorial/machine_learning_map/index.html)
簡單來說,當我們發現一個問題之後,如果你的資料大於50筆,就可以繼續,而如果少於50的話,你必須收集更多資料,不然整個機器學習的成功率會降得很低。
而上面這張圖,可以將這個問題分成四個模式來處理分別是:
1.classification(分類):
就如同字面上的意思,就是能夠透過觀察資料去預測出結果是屬於哪一種類的方法,最常見的例子就是二分法了,也可以回答"是"或"否"的這種問題。
2.clustering(分群):
通常是用來處理「沒有正確回答的問題」,clustering可以將有相同特徵的資料群集在一塊。
像K-means Clustering 分群之後的示意圖:
這原本是有很多點點所組成的圖,而透過clustering可以將它們類似的分成一群,分類方法為:
(0.0) (0.1)X軸為0,Y軸介於0到1的是紅色
(1.0) (1.1)X軸為1,Y軸介於0到1的是藍色
(2.0) (2.1)X軸為2,Y軸介於0到1的是綠色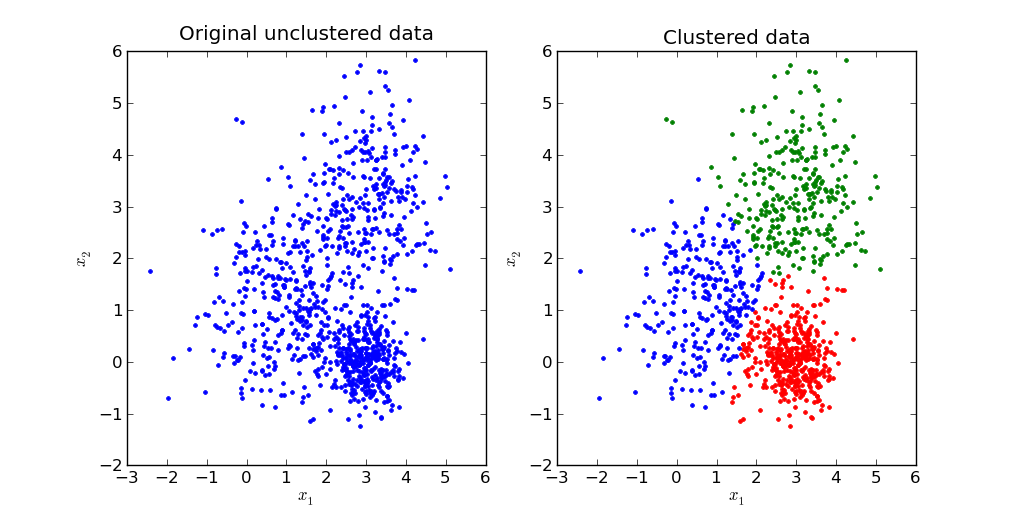 (圖片來源:http://pypr.sourceforge.net/kmeans.html)
(圖片來源:http://pypr.sourceforge.net/kmeans.html)
3.regression(回歸):
與前者 Classification 方法的不同之處,在於 Regression 演算法通常是預測出一個「數值」。
比如:明天的台北股市收盤價是多少? 如何根據所在城市、坪數、學區等來預測房價? 都是適合使用 Regression 演算法的問題。
4.dimensionality reduction(維度縮減):
簡單來說,一個問題,可能有好幾個原因影響這個問題的答案,而這個維度縮減可以將這好幾個原因壓縮成少數的關鍵原應,並不是直接選兩個,而是影想越大的權重月重,越不重要的壓縮的權重越小。
我們用圖來解釋:
(圖片來源:http://murphymind.blogspot.com/2017/07/machine-learning-dimensionality.html)
由上圖可以發現,相關性最大的紅色,在合併前後並沒有太大的位移,而相關性比較少的黑色和藍色,經過壓縮後,不同的兩點機乎重合在一起。