如何尋找較好的參數?
廢話不多說,直接上之前的程式碼
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
isir = load_iris()
x = isir.data
y = isir.target
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=4)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(x_train,y_train)
print(knn.score(x_test,y_test))
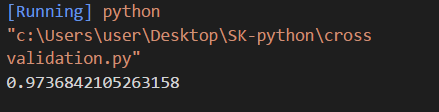
打印出來的結果有97%這麼高,不過這樣只是將我們的資料單純的切了一次,分成 test 和 Train 的部分,這麼做不是不好,只是有點不夠嚴謹,我們嘗試將資料的每一段當過test 這樣測出來的結果會比較準確
交叉驗證法
程式碼
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
isir = load_iris()
x = isir.data
y = isir.target
knn = KNeighborsClassifier(n_neighbors=5)
scores = cross_val_score(knn,x,y,cv=5,scoring = 'accuracy')
print(scores.mean())
這次我們引入了新的一種計分方式,它不再是一組一組看,它可以幫你統計多組資料然後輸出它的評分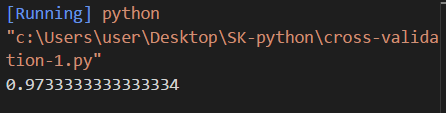
經過這樣之後有了五組的成績在作加總平均這樣說出來的會比較嚴謹
那我們現在來看n_neighbors的參數到底哪個比較好
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
isir = load_iris()
x = isir.data
y = isir.target
k_rang = range(1,31)
k_scores = []
for k in k_rang:
knn =KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn,x,y,cv=10,scoring = 'accuracy') #for classification
k_scores.append(scores.mean())
plt.plot(k_rang,k_scores)
plt.xlabel("value of k for knn")
plt.ylabel("cross-validated accuracy")
plt.show()
跟上一段程式碼差不多,只是加了k從1到31的for迴圈,並用專門給classification模組測試的指令去分析,並畫成圖輸出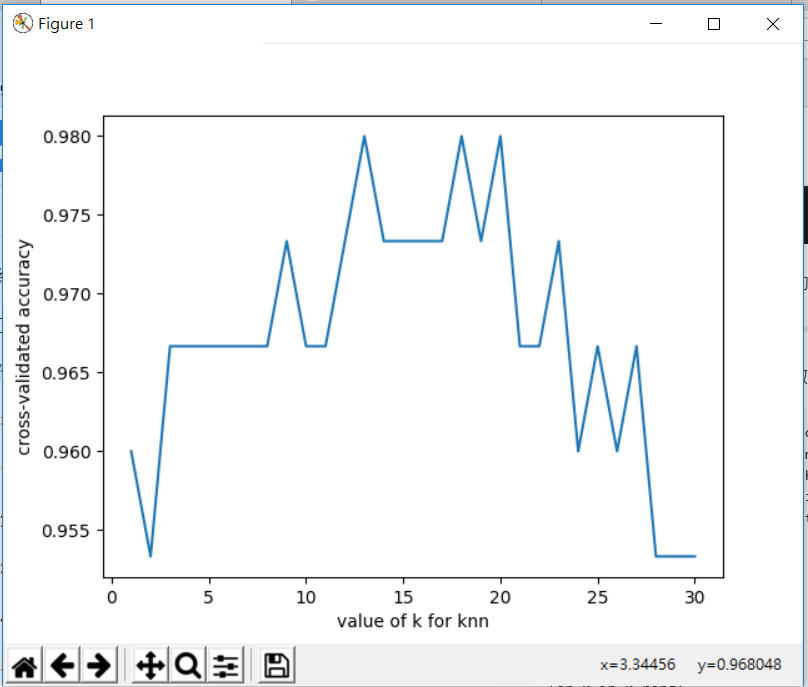
從圖中可以了解,在classification模組中,k在13到20有最好的成功率,無論k在變大或著變小都沒有哪麼好的成功率
現在把測classification的指令改成測試regression的指令
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
isir = load_iris()
x = isir.data
y = isir.target
k_rang = range(1,31)
k_scores = []
for k in k_rang:
knn =KNeighborsClassifier(n_neighbors=k)
loss = -cross_val_score(knn,x,y,cv=10,scoring= 'mean_squared_error')#for regression
scores = cross_val_score(knn,x,y,cv=10,scoring = 'accuracy') #for classification
k_scores.append(loss.mean())
plt.plot(k_rang,k_scores)
plt.xlabel("value of k for knn")
plt.ylabel("cross-validated accuracy")
plt.show()
程式碼跟剛剛一樣,只是加入loss那一行,我們來看看結果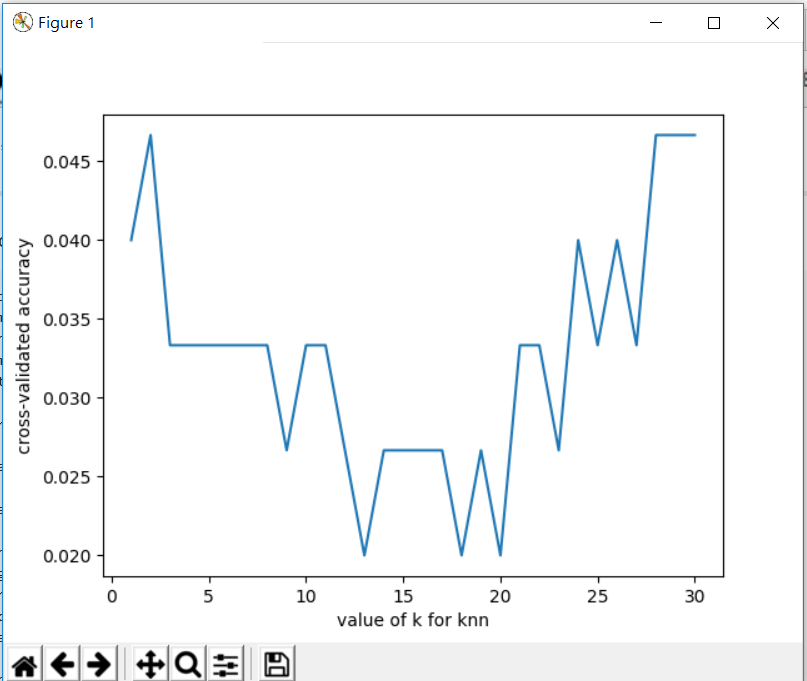
可以看到是指誤差越小,精確度越高,而跟剛剛的那個圖一樣,k介於13到20之間有最好的效果