通用學習模式
scikit-learn已經將所有的機器學習模式整合統一起來ㄌ,所以了解一個就可以通殺其他的模式。
在scikit-learn中本身就有許多數據庫可以用來測試。這次以 Iris 的數據為例,這種花有四個屬性,花瓣的長寬,莖的長寬,根據這些屬性把花分為三類。我們要用 分類器 去把四種類型的花分開。 這次用 KNN classifier,就是選擇幾個臨近點,綜合它們做個平均來作為預測值。
這次用 KNN classifier,就是選擇幾個臨近點,綜合它們做個平均來作為預測值。
程式碼部分
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
我們先引入sklearn的數據庫,這次用的classifition來學習這次的問題。
iris = datasets.load_iris()
iris_x = iris.data
iris_y = iris.target
iris就是上面說的那種花的名字。
iris_x = 就是這種花所有的屬性,有四種屬性
iris_y = 就是這種花分類,有三種分類
我們分別將iris_x iris_y打印出來看看
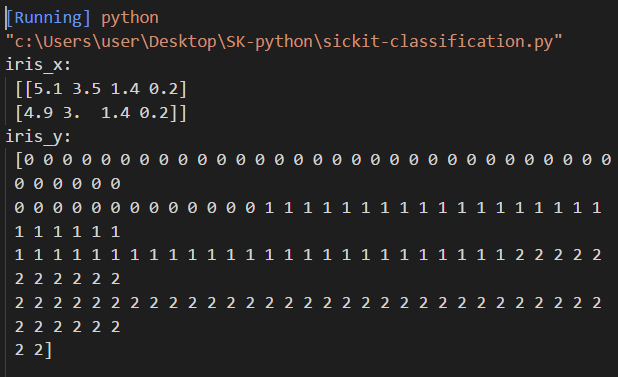
print ("iris_x:\n",iris_x[:2,:])
print ("iris_y:\n",iris_y)
現在我們用train_test_split模組,把要學習的跟測試的資料分開,這樣兩邊的資料不會互相影響
x_train, x_test, y_train, y_test = train_test_split(
iris_x, iris_y, test_size=0.3)
程式碼的意思就是將原有得總數拒拆成train跟test兩種,而test數據占全部的30%
我們再將y_train打印出來看看裡面是甚麼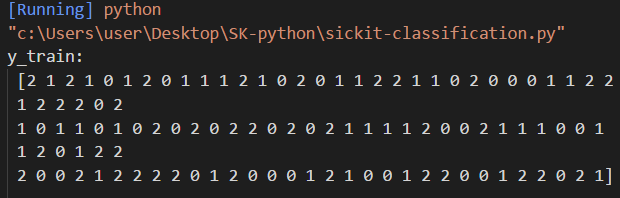
可以很清楚地發現這裡的資料被打亂了,這樣在機器學習中財部會因為有連續相同出現的數值所干擾導致學習有誤差。
接下來我們要來定義要用哪個模組來當學習方式
knn=KNeighborsClassifier()
knn.fit(x_train,y_train)
print(knn.predict(x_test))
print(y_test)
我們將knn定義成KNeighborsClassifier
knn.fit()就是將你要學習的資料放入,它就會幫你學習好
最後我們打印出經過knn所預測的x_test來跟原本的y_test做對照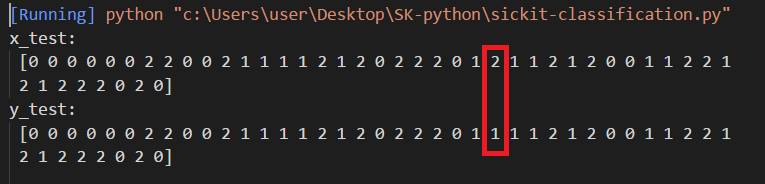 預測值與對照值有一點點的誤差,這就是機器學習的本質,它沒有辦法弄出完完全全一模一樣的數據,它只能大概的模擬出差不多的數據。
預測值與對照值有一點點的誤差,這就是機器學習的本質,它沒有辦法弄出完完全全一模一樣的數據,它只能大概的模擬出差不多的數據。
這些就是scikit-learn中通用學習模式的例子。