Scikit-Learn的datasets
在一開始,講到機器學習時,就有提到我們為了讓機器學習一個問題,必須準備許多的資料,好讓它去建立起這個問題的模型,但是,我們如果想測試,但是身邊沒有那麼多資料時該怎麼辦呢?
在Scikit-Learn中的datasets已經幫我們建立了許多的資料範例: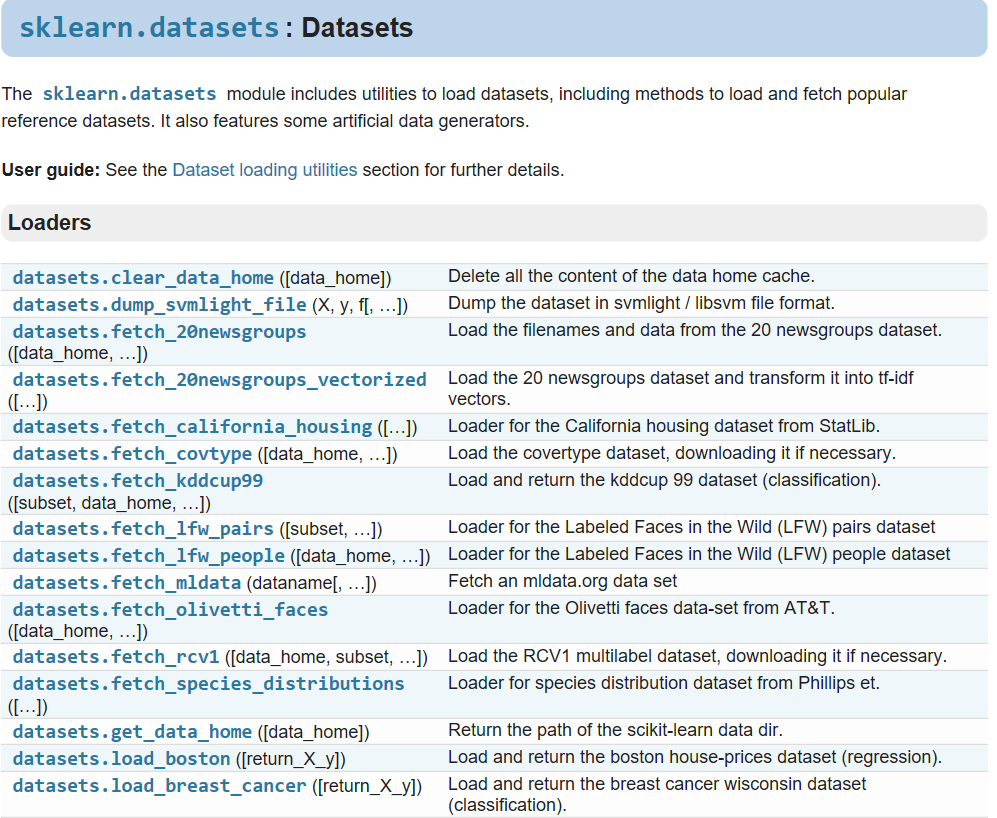 (圖片來源:http://scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets)
(圖片來源:http://scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets)
在圖中,我們可以看到已經內建了許多筆的資料可以滿足我們想要測試的需求,像我們在上一章中提到的iris在這裡也能找到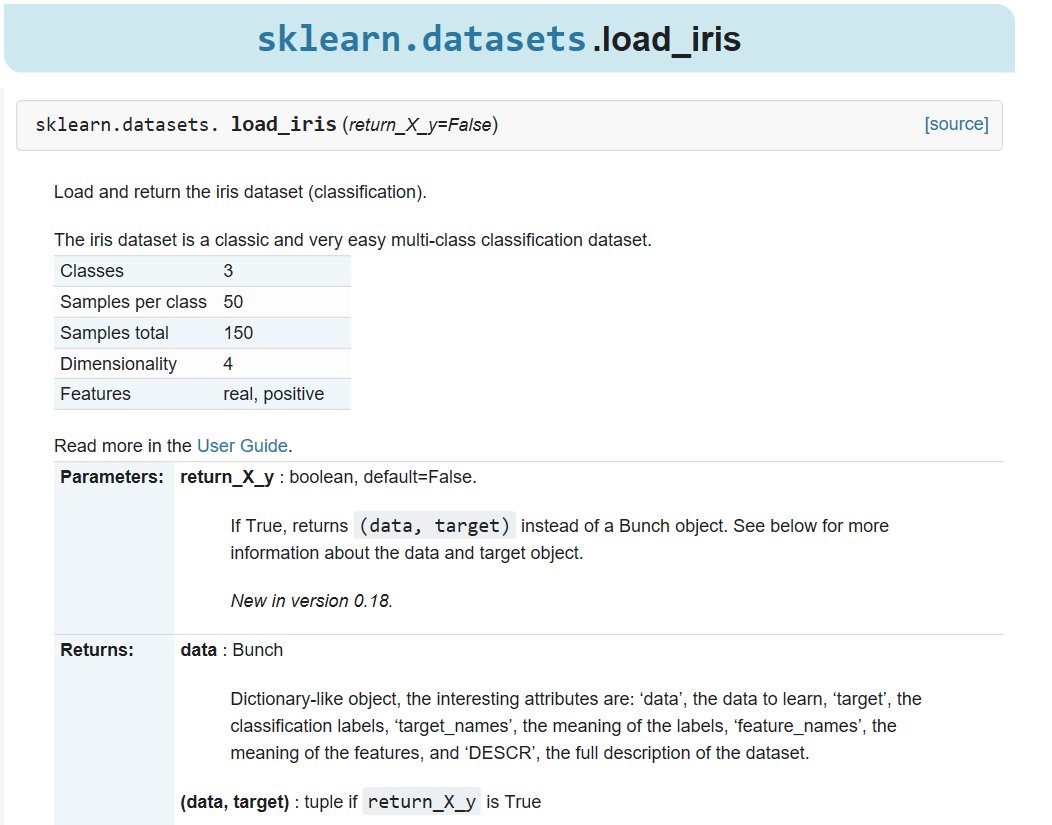 裡面就有說到這個iris中有的參數內容,就跟我們在上一篇中所提到的一樣。
裡面就有說到這個iris中有的參數內容,就跟我們在上一篇中所提到的一樣。
看到這麼多筆資料,我們就來試試看吧!
我們用boston的房價來做測試,測試之前,我們先來看看boston的內容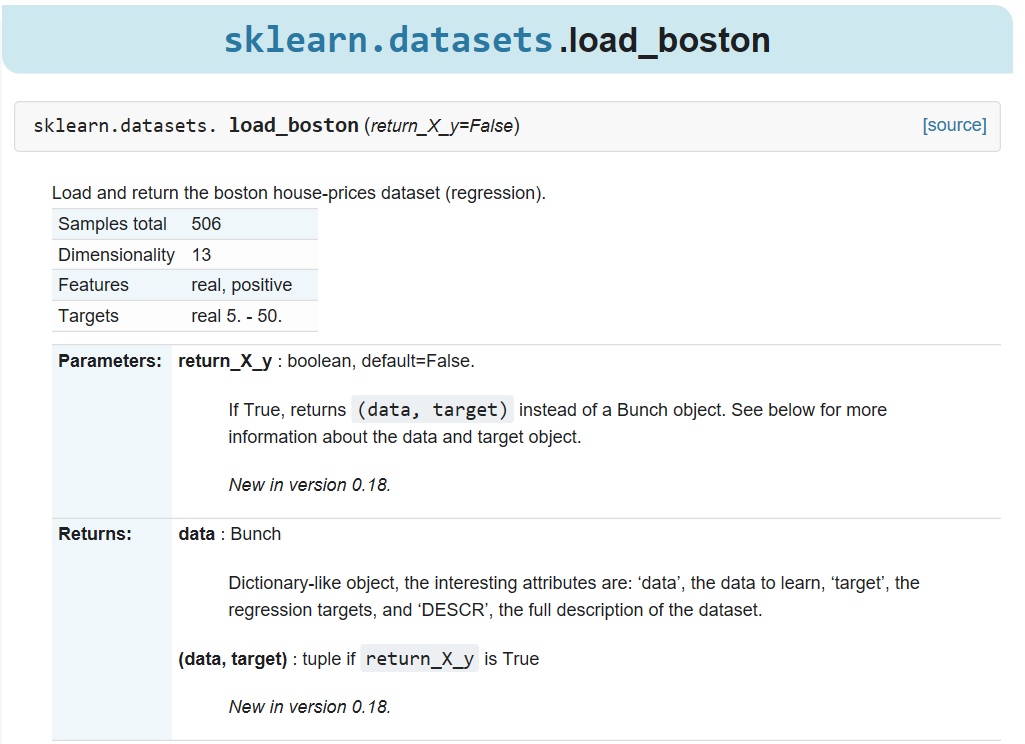 (圖片來源:http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_boston.html#sklearn.datasets.load_boston)
(圖片來源:http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_boston.html#sklearn.datasets.load_boston)
程式碼的部分:
from sklearn import datasets
from sklearn.linear_model import LinearRegression
loaded = datasets.load_boston()
data_x = loaded.data
data_y = loaded.target
model = LinearRegression()
model.fit(data_x,data_y)
print("data_x:\n",model.predict(data_x[:4]))
print("data_y:\n",data_y[:4])
首先我們先import sklearn所需要的參數,並將boston的資料匯入程式中,並將他們分別依照data和target的不同匯入指定的項目中,
接著,我們建立一個模型,LinearRegression至於這個是甚麼呢,我們一樣去scikit的網站看看 (圖片來源:http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html)
(圖片來源:http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html)
它是一個已經被寫好了模組,是屬於迴歸分析的一種,裡面有像fit等函數。
既然這樣,我們就把資料學習一下吧,當我們fit完了之後,便可以打印出我們預測的質和對照值
看完這組數據,我們發現其實存在的不少誤差,而為甚麼會這樣呢?問題就是在我們的使用的模型,在機器學習中,我們要去測試不同的模組,找到最好的之後,還要去測試不同的參數,甚至連不同的資料處理方式都要去測試與確認,才能達到最好的效果。