標準化數據normalizatio
這個名詞看起來很複雜深奧,其實沒有哪麼難,我們小時候一定有用過。不知道大家在國高中時有沒有很在意自己的段考成績?如果有的話應該知道結算名次時會看的是總成績平均,恩,總成績,如果你有很多科考試,你是不是一定要拿計算機呢?我記得我小時候算這種東西都喜歡取一個中間數,然後以正負的方式算我的成績,例如:90,85,60,50,48這五個成績好了,我就會用60當作基準點90就變成+30,85則是+25,50是-10,48是-12,然後我只要將60*5+30+25-22=333了,其實這就是標準化的概念。我們想辦法去縮短資料和資料之間的差距,來達到簡化資料的複雜度。
而在Scikit-Learn裡就有這項功能,我們來測試看看
from sklearn import preprocessing
import numpy as np
a = np.array(
[
[10,2.7,3.6],
[-100,5,-2],
[120,20,40],
],
dtype=np.float64
)
print("un-normalization:\n",a)
print("normalization:\n",preprocessing.scale(a))
首先,我們引入我們要的資料,並創建一個名字叫a的陣列,然後利用scikit中的參數,我們就可以將這筆資料標準化
我們來看看輸出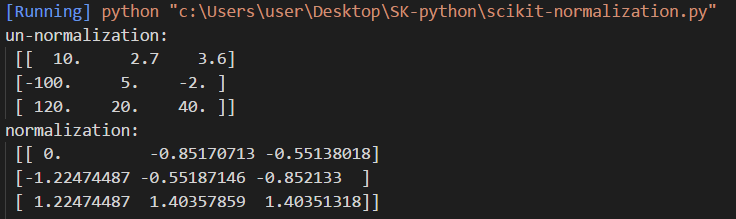
我們可以很清楚地發現,資料的間距變小了,這樣會幫助機器學習提高它的成功率。
只看這樣體會不出來,我們來實測一次機器學習如果沒有標準化有沒有差
from sklearn import preprocessing
from sklearn.cross_validation import train_test_split
from sklearn.datasets.samples_generator import make_classification
from sklearn.svm import SVC
import numpy as np
import matplotlib.pyplot as plt
x, y = make_classification(n_samples=300, n_features=2 , n_redundant=0, n_informative=2,
random_state=22, n_clusters_per_class=1, scale=100)
plt.scatter(x[:,0],x[:,1],c=y)
plt.show()
這次我們一樣先引入一些待會要用到的套件,而這次我們測試的資料自己生成,生成有300個點,兩種屬性等,那我們來看看這樣的數據會是長怎樣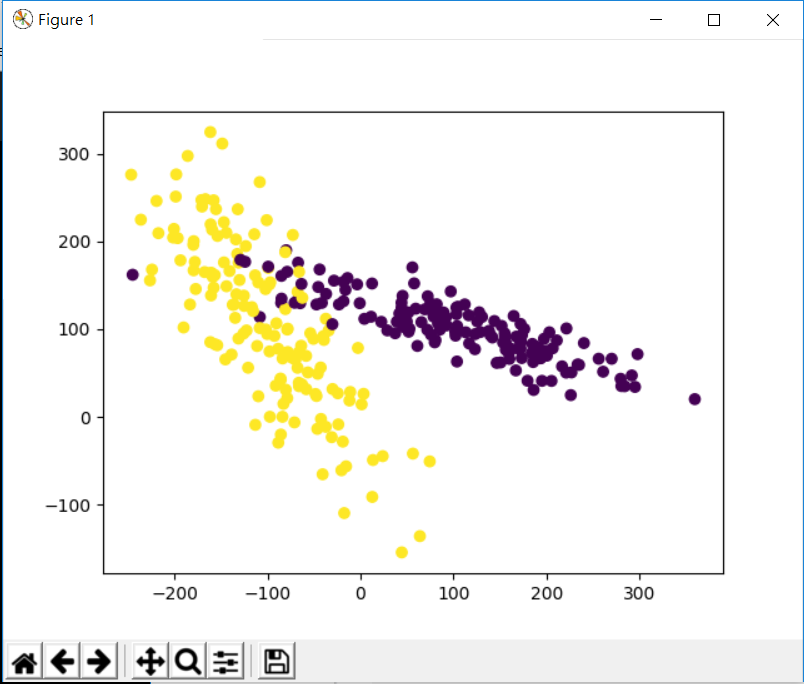
這是我們這次要處理的資料,我們可以很清楚地用肉眼分辨有兩組不同的點
x = preprocessing.scale(x)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=8)
clf = SVC()
clf.fit(x_train,y_train)
print(clf.score(x_test,y_test))
接著我們將資料標準化後,並用將它導入機器學習,然後用上一節課所教的score參數打印出分數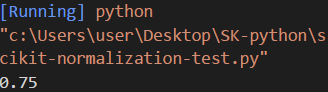
成功率有75%,相當的高
那我們將標準化數據的那行移除,並在執行一次程式
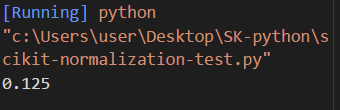
成功率瞬間下降到1成左右,由此可以知道,資料的標準化會大大的影響機器學習的效果